
Expert and Novice Learning: Predictive Processing Insights

In response to:

As part of my process of understanding “Predictive Processing”, the latest thinking in cognitive/neuroscience on how cognition works, I think the idea that working memory is a temporary copy of long-term memory is a major limitation/misconception, and the idea that we need some kind of special version of working memory that experts can access is making things too complex.

In predictive processing, prior knowledge/skill schema and mental models stored in Long Term Memory are activated, and in combination with “what has just happened” in working memory, they make a prediction of reality. This prediction is used to model what the senses should see and are compared to what the senses are currently detecting.
If it matches well enough, carry on predicting. If there are prediction errors, adjust the schema, mental models, and parameters of your prediction to get a better-fitting prediction. The mind /body is a self-organising prediction error minimisation system.
See my blog for a more detailed explanation of predictive processing:
Also, watch the excellent talks by Andy Clark and Anil Seth:
How the brain shapes reality – with Andy Clark
Consciousness in humans and other things with Anil K Seth | The Royal Society
In predictive processing, there is not a working memory limit but rather a limit on the bandwidth of prediction errors. Novices hit that limit early, but experts will likely not. They both have the same limitation on error bandwidth; the experts are just better at predicting!
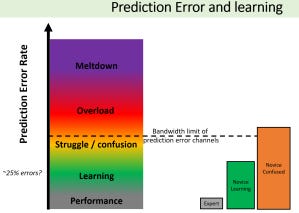
The expert can retrieve a good set of schema and mental models appropriate for the context, which allows them to predict the answer/solution well and minimise their prediction errors.
The novice doesn’t have the same set of schema and mental models, or at least they may not be experienced in applying them in the specific context. As such, they have a much higher level of prediction errors.
If those prediction errors exceed their prediction error bandwidth, then they won’t be able to assemble an effective prediction, leaving them confused/ overwhelmed.
Our job as teachers is to ensure the learning task generates sufficient prediction errors so that they will update their schema and mental models to predict this situation better in the future, but not too much so they are overwhelmed. We can do this by using all the ways we know how to manage cognitive load. We can ensure relevant prior knowledge is activated, we can provide a worked example, we can provide scaffolding / reverse fading, we can ensure the task structure is familiar if it is the content that needs learning, or we can ensure the content is familiar if it is the task structure/method that needs learning. We can ensure extrinsic load is minimised i.e. things not related to the learning task are predictable / routine. This is across all senses, including the 33 interoceptive ones!
When we are thinking about getting prediction error in the right range for learning, we can focus on predictability rather than on task difficulty, content, or element interactivity. Which parts of this task are predictable by this student, at this time, in this room, with this group of people with what I have established they know already? I want to generate the “surprise” in the area I want them to learn and I want everything else highly predictable.
I don’t have documented research to back this up(yet), but I think as the schema and mental models are being used to make predictions, they reside in LTM and are just activated. We can consider that there is a level of “working memory” that keeps track of the causal/temporal links that are useful to making the prediction which ensures long-term memory-based schema/mental models are activated.
In my past life (before teaching!) I did software engineering, so I think of working memory as storing a list/array of pointers to where the schema/mental models in LTM are stored.

Predictive processing proposes that there is a structural structure that spans several linked layers from high-level concepts down to low-level sensory states, with predictions and prediction errors feeding forward and backwards up and down the stack.
Each level of this hierarchy is linked to Long-Term Memory. At low levels, we can think of visual processing patterns of retinal pixels using shape schema, and at high levels, we process intentions and emotions in context.
In the example of comprehending that there is a full cup of coffee in front of us, we can see and imagine the interactions with long-term memory at each level within the hierarchy.
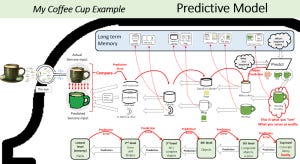
In conclusion, I think the architecture proposed in predictive processing ( also known as active inference-predictive coding) helps simplify the seeming challenges in interpreting the simple model of working memory in the face of how experts and novices experience the same task activity and how we, as teachers can think about being “prediction error managers” to get our more expert learners, our novice learners into the optimum learning zone.
Please come and join a community to help develop ideas about how predictive processing can be applied in education. Then, join the Cogscisci Discord group and see the “Predictive Processing” channel. Post questions, challenges, interesting research, and comment on people’s posts to contribute to the debate..